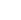说到高性能网络编程,我们第一时间想到的是epoll机制,epoll很长一段时间统治着整个网络编程江湖,然而io_uring的出现,似乎在撼动epoll的统治地位,今天我们来揭开io_uring的神秘面纱。

创新互联公司2013年成立,先为中方等服务建站,中方等地企业,进行企业商务咨询服务。为中方企业网站制作PC+手机+微官网三网同步一站式服务解决您的所有建站问题。
1.io_uring简介
io_uring是一个Linux内核的异步I/O框架,它提供了高性能的异步I/O操作,io_uring的目标是通过减少系统调用和上下文切换的开销来提高I/O操作的性能。
io_uring通过使用环形缓冲区和事件驱动的方式来实现高效的异步I/O操作。
io_uring的设计使得应用程序可以同时处理大量的I/O操作,从而提高系统的吞吐量和响应速度。
2.io_uring实现原理
io_uring整体架构如下:
图片
2.1基础概念
- SQE:提交队列项,表示IO请求。
- CQE:完成队列项,表示IO请求结果。
- SQ:Submission Queue,提交队列,用于存储SQE的数组。
- CQ:Completion Queue,完成队列,用于存储CQE的数组。
- SQ Ring:SQ环形缓冲区,包含SQ,头部索引(head),尾部索引(tail),队列大小等信息。
- CQ Ring:CQ环形缓冲区,包含SQ,头部索引(head),尾部索引(tail),队列大小等信息。
- SQ线程:内核辅助线程,用于从SQ队列获取SQE,并提交给内核处理,并将IO请求结果生成CQE存储在CQ队列。
2.2 io_uring系统调用
- io_uring_setup():用于初始化io_uring环境,创建io_uring实例。
- io_uring_enter():用于提交和等待io_uring操作的系统调用,可以指定提交的操作数量和等待的超时时间。
- io_uring_register():用于注册文件描述符或事件文件描述符到io_uring实例中,以便进行I/O操作。
2.3 liburing库
liburing是一个用于Linux的用户空间库,用于利用io_uring接口进行高性能的异步I/O操作,它提供了一组函数和数据结构,使开发者能够更方便地使用io_uring接口。
- io_uring_queue_init:初始化一个io_uring队列。
- io_uring_register:将文件描述符注册到io_uring队列中。
- io_uring_prep_read:准备一个读取操作。
- io_uring_prep_write:准备一个写入操作。
- io_uring_submit:提交一个或多个操作到io_uring队列中。
- io_uring_wait_cqe:等待一个完成的操作。
- io_uring_cqe_seen:标记一个完成的操作已经被处理。
- io_uring_queue_exit:关闭并释放io_uring队列。
2.4 工作流程
- 创建io_uring对象:首先,需要创建一个io_uring对象,可以使用io_uring_setup()函数来完成。
- 准备I/O请求:在进行I/O操作之前,需要准备相关的I/O请求。可以使用io_uring_prep_XXX()系列函数来准备不同类型的I/O请求,例如io_uring_prep_read()用于读取数据,io_uring_prep_write()用于写入数据。
- 提交I/O请求:准备好I/O请求后,可以使用io_uring_submit()函数将请求提交给内核,内核会将这些请求放入一个队列中,等待执行。
- 等待IO请求完成:可以使用io_uring_wait_cqe()函数来等待I/O请求的完成,一旦请求完成,内核会将完成事件放入一个完成队列中。
- 获取IO请求结果:可以使用io_uring_peek_cqe()函数来获取完成队列中的完成事件。然后,可以通过事件的信息来处理完成的I/O请求,例如读取数据或者处理错误。
- 释放IO请求结果:获取完IO请求结果,使用io_uring_cqe_seen()函数来释放IO请求结果,以便内核可以继续使用。
- 重复执行:可以重复执行上述步骤,以处理更多的I/O请求。
3.内核实现
3.1 创建io_uring对象
图片
用户程序通过io_uring_setup系统调用创建和初始化io_uring对象,io_uring对象对应于struct io_ring_ctx结构体对象。
io_uring_setup主要工作:
- 创建struct io_ring_ctx对象并初始化。
- 创建struct io_urings对象并初始化,注意此时已完成CQ和所有CQE创建。
- 创建SQ和所有SQE并初始化。
- 如果struct io_ring_ctx对象flags参数设置IORING_SETUP_SQPOLL,则创建SQ线程。
3.2 fd绑定io_uring对象
图片
已创建的io_ring对象需要和fd进行绑定, 以便能够通过fd找到io_uring对象,创建一个新的file,file private_data成员指向io_ring对象,申请一个未使用的文件描述符fd,fd映射至file,并存储在进程已打开文件表中。
注意:mmap内存映射需要用到该fd。
3.3 io_uring对象内存映射
图片
通过io_uring_setup系统调用创建完io_uring对象后,用户程序还不能直接访问io_uring对象,此时用户程序需要通过mmap函数将io_uring对象SQ,CQ以及head和tail等相关内存空间映射出来。
完成mmap内存映射后,io_uring对象相关内存空间成为用户程序和内核共享内存空间,用户程序可以直接访问io_uring对象,不再需要通过执行系统调用访问,很大程度上提高了系统性能。
3.4 提交IO请求
图片
SQ Ring中有两个成员head(头部索引)和tail(尾部索引),头部索引指向SQ队列第一个已提交IO请求,尾部索引指向SQ下一个空闲SQE。
提交IO请求,只需要将tail指向的SQE填充IO请求信息,并让tail自增1,指向下一个空闲SQE。
注意:head和tail不是直接指向SQ数组,而是需要通过head&mask和tail &mask操作指向SQ数组,mask数组为数组长度减1,因为数组有固定大小,所以需要通过&mask方式防止越界访问数组,这种方式可以让数组形成一个环形缓冲区。
3.5 等待IO请求完成
图片
IO请求的处理有两种方式:
- 方式1:SQ线程从SQ队列中获取SQE(已提交IO请求),并发送给内核处理。
- 方式2:用户程序通过io_uring_enter系统调用从SQ队列中获取SQE(已提交IO请求),并发送给内核处理。
从SQ队列获取SQE只需要获取SQ Ring head指向的SQE,并让head自增指向下一个SQE即可。
图片
内核处理完IO请求后,SQ线程会申请CQ Ring tail指向的CQE存储IO请求结果,tail自增1指向下一个空闲CQE。
3.6 获取IO请求结果
图片
用户程序通过判断CQ Ring head和tail之间的差值,可以检测到是否有已完成IO请求,如果有已完成IO请求(CQE),获取CQ Ring head指向CQE,获取IO请求结果。
3.7 释放已完成IO请求
释放已完成IO请求只需要将CQ Ring head指针自增1指向下一个CQE即可,这样做的目的是防止重复获取IO请求结果。
io_uring为什么高效?
核心原因:io_uring通过mmap内存映射大大减少了系统调用,在高并发场景下,系统调用非常损耗系统性能。
其他原因:
- 减少拷贝:io_uring通过共享内存减少用户程序和内核数据拷贝。
- 批量操作:io_uring支持批量操作,一次性可以提交多个I/O请求,减少系统调用的次数,提高系统效率。
- 无锁环形队列:io_uring采用无锁队列实现用户程序与内核对共享内存的高效访问。
网站题目:图文详解io_uring高性能异步IO架构(原理篇)
分享路径:
http://cdbrznjsb.com/article/cccjsej.html